









Sometimes, the best way to start a conversation is to state the obvious: Artificial intelligence is the most disruptive technology since…let me think for a moment…the smartphone, IMHO. Venture capitalists are placing big bets on it. From January to July 2023, investors sank more than $40 billion into AI start-ups, while globally VC money fell 48% in other start-ups.* The year kicked off with an estimated $10 billion in funding for OpenAI by Microsoft. Just like the smartphone, AI will be part of almost everyone’s life. It doesn’t get much more disruptive than that.
I’m motivated personally and professionally. I’m excited about AI because it gives me an opportunity to learn something completely new, identify the challenges with it, and then figure out how data centers fit into the technology now and in the future.
An AI development milestone – the ability to manage and analyze unstructured data – was reached in the late 1990s. That was about 40 years after Alan Turing created the Turing Test, setting criterion for showing that a computer can “think,” which is distinctly different from performing calculations or executing a process using structured data. What you are reading now is unstructured data. Video, audio, documents and social media posts are unstructured data. Around 80% of enterprise data is unstructured.
Being able to extract information from unstructured data is the breakthrough that brought us to today’s AI. The confluence of GPU processing, AI algorithms, low-latency networking, high-density power and high-performance compute has enabled achieving a passing grade on the Turing Test. You’ll notice I didn’t say we got an A, or even a B. While I can’t precisely grade the achievement based on what I’ve learned so far, I can confidently say that we are only at the beginning of what Bill Gates calls “the Age of AI.”
Welcome to the AI Matrix
If you work with me, you know that I’m a big fan of metaphors. Here’s one for my take on AI’s stage of development.
There’s a scene early in The Matrix where our protagonist, Neo, is connected to a computer through a port in the back of his neck, then trained in martial arts and other soon-to-be-useful skills. His brain is flooded with a massive amount of data and he is put into virtual reality simulations to further refine the model. He also experiences the real world (instead of the computer program that is the matrix) discovers he can use his mind to bend spoons by realizing “there is no spoon,” that it’s only a computer simulation, and is put to the test by the

Deeper Dive Into AI Model Training
As I said, I’m learning about AI. The old saw, “garbage in, garbage out,” rings true with AI model training. One study shows that it’s essential to train generative AI using human-produced data. Training with synthetic data can cause “model collapse.” Keep learning here
That’s similar to this point in AI’s story, from my perspective. AI models are being trained with unstructured data collected from all types of endpoints, and all that data will be very useful in the future. In the meantime, models are being real-world tested in AI tools such as ChatGPT, Bard and business analytics applications. They are being refined using enterprise process data and by scraping the internet for more training data, with the intent of accelerating time to value.
The bullets that need to dodged? Perhaps they are issues around data privacy and “the right to scrape.” How does bending spoons fit into my analogy? Distinguishing what’s virtual from what’s real could be challenging. Again, I think we are at a starting point, that disruptive technologies create concerns and history shows that we benefit in the long run by constructing guard rails.
Speaking as a data center professional, what’s critical for training AI models are densely connected, network-rich data centers that serve as a funnel between end points and AI-workloads. Low-latency networks and interconnections are conduits to AI-capable servers applying algorithms, making inferences and guiding decisions – by machines and people. Data needs to be uncorrupted, trusted, voluminous and, depending on use case, real-time. Supporting these real-time workloads increasingly depends on AI inference zones within data centers that are purpose-built to reduce latency and deliver the performance AI models require.
I say, “depending on use case” because I recently learned about healthcare research in which a supercomputer is being used to go back through legacy image data (MRIs and other patient data) to look for disease markers that cannot be detected by the human eye. They are also analyzing huge sets of public health data to determine why a particular region is affected by a disease while surrounding areas are not. With high-performance computing (HPC), researchers are making correlations by crunching data at unprecedented rate and scale, on data that’s been archived for years, and teasing out important information.
The Coalescing AI Data Center Ecosystem
“Depending on use case” also applies to the different types of data centers. Requirements relevant to power, space and cooling will vary on a sliding scale of sorts. We already see AI executing in Internet of Things devices such as those used in manufacturing, and self-driving tractors in farming. These are edge applications that require relatively small amounts of power, space and environmental control. I recently found this diagram showing the flow of data and training models in edge AI.
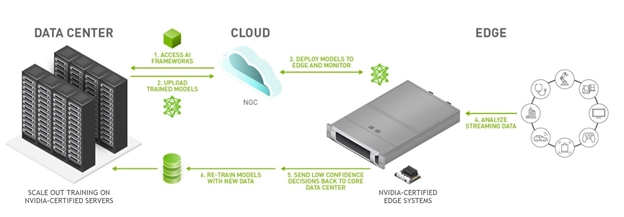
At the other end of the spectrum are hyperscale data centers. Amazon Web Services has deployed clusters of up to 20,000 GPUs in a data center. I won’t speculate on the amount of energy that scale of compute consumes, but I will say that both the power and bandwidth required are “enormous,” to borrow a superlative from the article I referenced. Likewise, adequately cooling server clusters of this magnitude is an enormous data center deployment challenge.
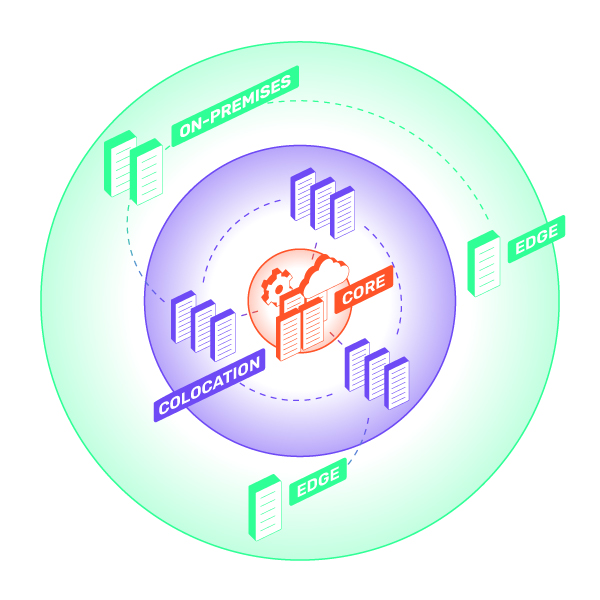
Data centers on the scale CoreSite operates are positioned in a zone between the two ends of the spectrum. Because of the network density, they also can be data conduits between edge and hyperscale, a “sweet spot” for AI workloads requiring high density power and compute, with direct connection to cloud as well as low-latency interconnection to edge and on-premises data centers.
Our Clients Are the AI Experts
One thing I want to make clear is that our clients are the AI experts and innovators – CoreSite data centers help facilitate our customers’ AI development and execution. For example, an automotive company developing self-driving cars and delivery systems uses one of our facilities to aggregate data collected each day by test vehicles, then relay it to training models in a public cloud. The next day, vehicles canvass the city and return to transfer information.
Media companies have been leveraging CoreSite colocation for many years to render imagery in GPU-powered deployments and streamline workflows amongst multiple stakeholders. That’s exactly the same type of high-performance computing and low-latency interconnection requirements characteristic of AI. For us, it’s proof of concept that we can accelerate AI development and have a valuable place in the dynamic, coalescing AI data center ecosystem.
What I Learned at AI4 2023
I went to the AI4 2023 Conference in August with the mindset that I was there to continue learning about AI. By the way, CoreSite was a sponsor at that conference, and I want to say thanks to all the people who visited our booth. We truly appreciate the interest!
What struck me as remarkable was the number of data scientists, developers and data analysts in attendance. We hear all the time about the volume of data AI produces. However, it’s clear that data management, data integrity and data relevance are keys to unlocking business-critical inferences.
I also had not anticipated seeing people from companies that are developing and delivering AI-specific services. In retrospect, it makes sense. They are part of the rapidly growing community of start-ups, SMBs and large enterprises that are excited and challenging themselves to realize the potential of AI.
What’s next for the symbiotic relationship between artificial intelligence and data centers? While I can’t predict the future, I can keep learning and talking about it. I encourage you to keep an eye out for my next post, where I’ll discuss the parallel between AI technologies and cloud evolution as well as new perspectives on the AI industry.
Teaser – One topic will be: How can we be sure to keep what’s valuable to our clients top of mind, especially in light of where they are in their digital transformation?
Know More
I invite you to visit the new AI industry solutions page on our website.